Robust Models
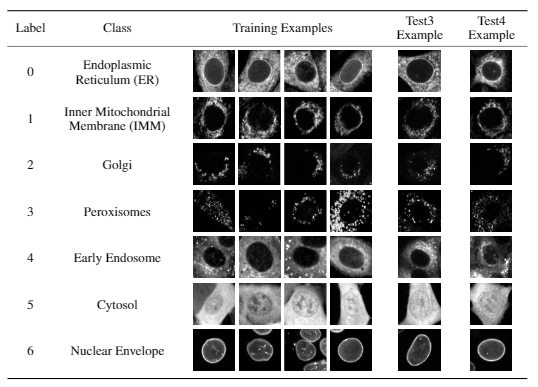
In addition to learning biological signal, a good machine learning model will be robust to non-biological, technical variation. Unfortunately, getting a model that learns just biological signal while ignoring technical variation can be difficult. Especially when you’re working with a purely data-driven model, both sources of variation can contribute to the predictiveness of the model. For example, large-scale image screens that parallelize many experiments at once might image experiments in the same order each time. The microscope gradually heats up as it operates, meaning the final set of experiments will be brighter than the first step of experiments, so the model might learn that image intensity can discriminate these experiments
While biological signal (hopefully) produces general information, technical variation does not. If you scrambled the order of experiments in new screens, you might see a drop in performance, if the model has indeed learned to rely on technical variation as part of its decision-making. A growing concern in machine learning is that we may be overestimating how generalizable models are with standard techniques. Typically, an expert will evaluate their method by holding out some data, and then evaluating performance on that data to simulate the condition where the classifier is given fresh, unseen data. However, these types of methods don’t capture the cases where there may be changes in the way the data is produced and generated - for example, different hospitals have different instruments, so classifiers shown to work on one hospital’s data will not always work as well for another’s.
To help machine learning experts develop methods that are robust to new data from different sources, we released a dataset where evaluation data increasingly differs from the data the experts are provided with to develop their models. For example, our hardest dataset comprises of data collected from a different laboratory in Ottawa, under a different microscope. We found that all of the current methods used to classify cells are not robust when the new data is different enough from the original data.
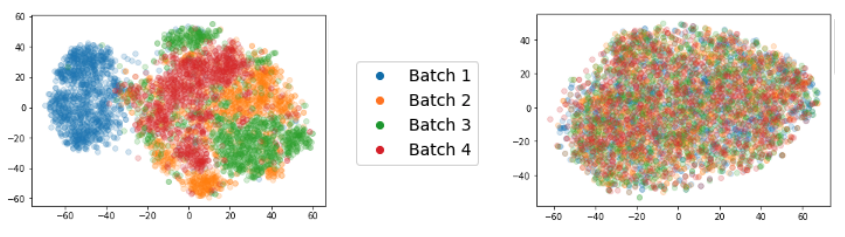
We found one surprisingly simple trick can make deep learning models robust to batch effects - simply by re-arranging the order of training data so all datapoints in the batch to the neural network are sampled from the same experiment. This trick interacts with batch normalization layers present in most modern deep learning architectures. These layers are typically meant to stabilize training, by making sure that the output of each convolutional layer in a neural network is scaled to the mean and standard deviation of a batch. We realized that these layers could also be used to “subtract” batch effects during training and inference: by averaging samples from the same experiment together, the biological treatment effects “cancel out”, leaving just the batch effects alone to be standardized out from individual datapoints. Despite its simplicity, this method is outstandingly effective, outperforming much more advanced approaches, and generalizing across different strategies including supervised classification, self-supervised representation learning, and even transfer learning strategies where new datasets employing different fluorescent markers are totally unseen.